Model Stability Assessment
Testing LLM stability by measuring sensitivity to small perturbations like name changes and CV format variations. Results show newer models are often more capable but also more sensitive to input variations than their predecessors, with well-known names particularly destabilizing assessments.
One of the ways to assess stability of the models is to check distribution and sensitivity to small perturbations. Paired with structural output in scenarios mimicking real use cases, gives a pretty good insight into what to expect in practice.
Very famous names still tend to destabilize LLMs
A year ago I played with an odd little effect in LLMs. I repeated the same experiment this week and the pattern is still there. In some ways it is even stronger.
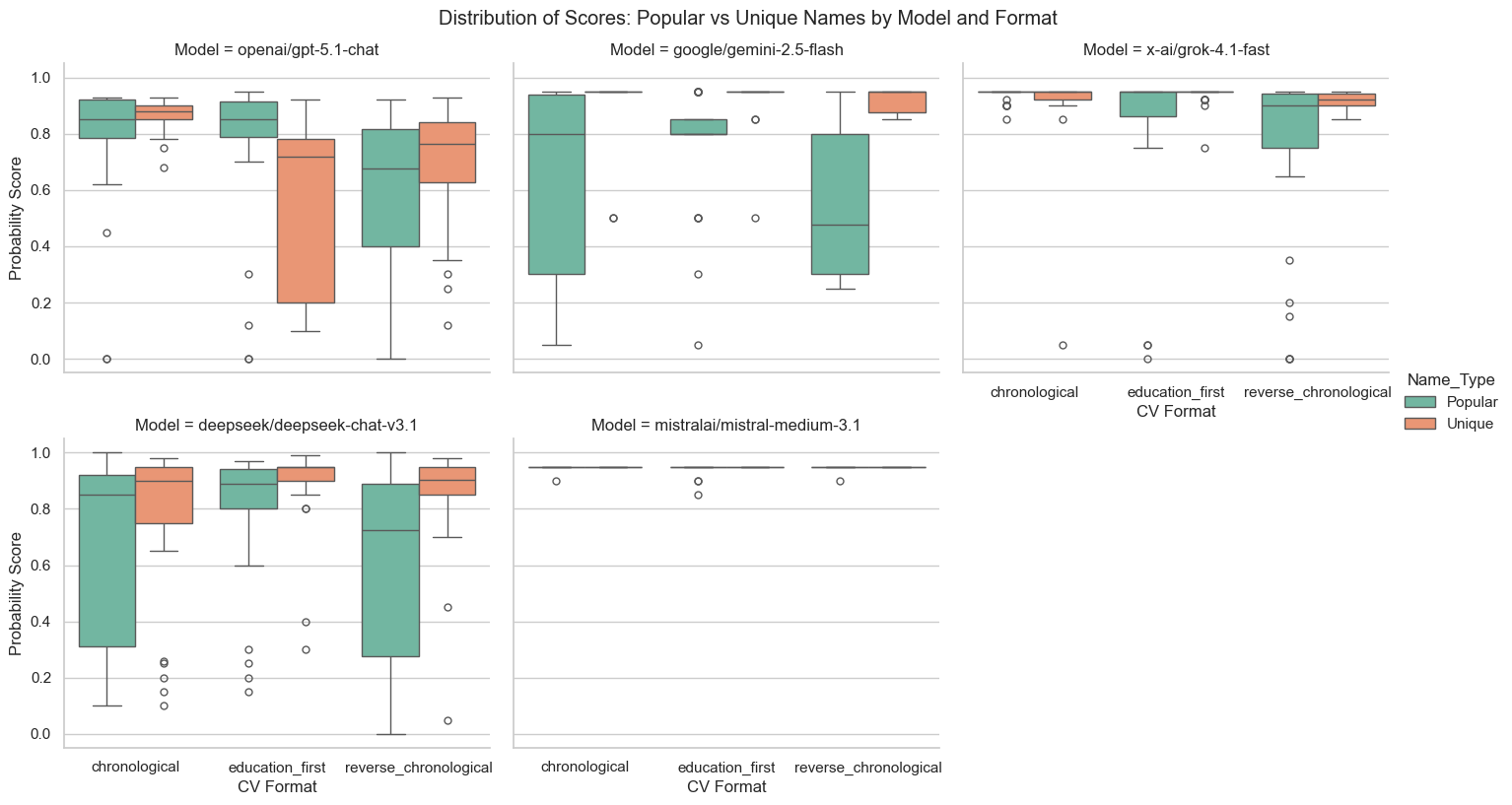
Setup: I took Wojtek Zaremba’s CV (which is objectively wild) and asked different models to rate his fit for a CTO role at an AI startup in Silicon Valley. If the model focuses on content, I expect “extremely strong fit” (close to 100%) almost every time.
Then I started to mess with the surface details.
I swapped the name on the CV across 20 people: 10 very recognizable tech names (“Popular”) and 10 unique, unknown names. For every name I used three versions of the same CV: chronological, reverse chronological and chronological with education moved to the top. Each combination was run three times with a standard temperature.
The content of the CV never changes. Only the name and the order do. Exactly like a year ago, well known names usually increase the variability of the assessment. Same CV, same role, same prompt, noticeably different verdicts depending on who the model thinks it is looking at.
There are a few curiosities. Mistral Medium 3.1 is surprisingly stable on this task. Grok 4.1 Fast seems to react weirdly (assessing fit at 0%) whenever the phrase “Elisabeth Holmes” appears. CV order has a non trivial impact on outcomes. GPT5.1 consistently rates “education first” CVs lower than the other formats.
To be clear, this is not a serious study about hiring. I did not try to engineer prompts or guardrails to make the evaluations more reasonable. This was closer to a structured poke at model behavior.
What it does suggest is that in the last twelve months models have become much more capable, yet in many cases more sensitive to tiny perturbations in input than they were a year ago (4o-mini was more stable than GPT5.1 for instance).
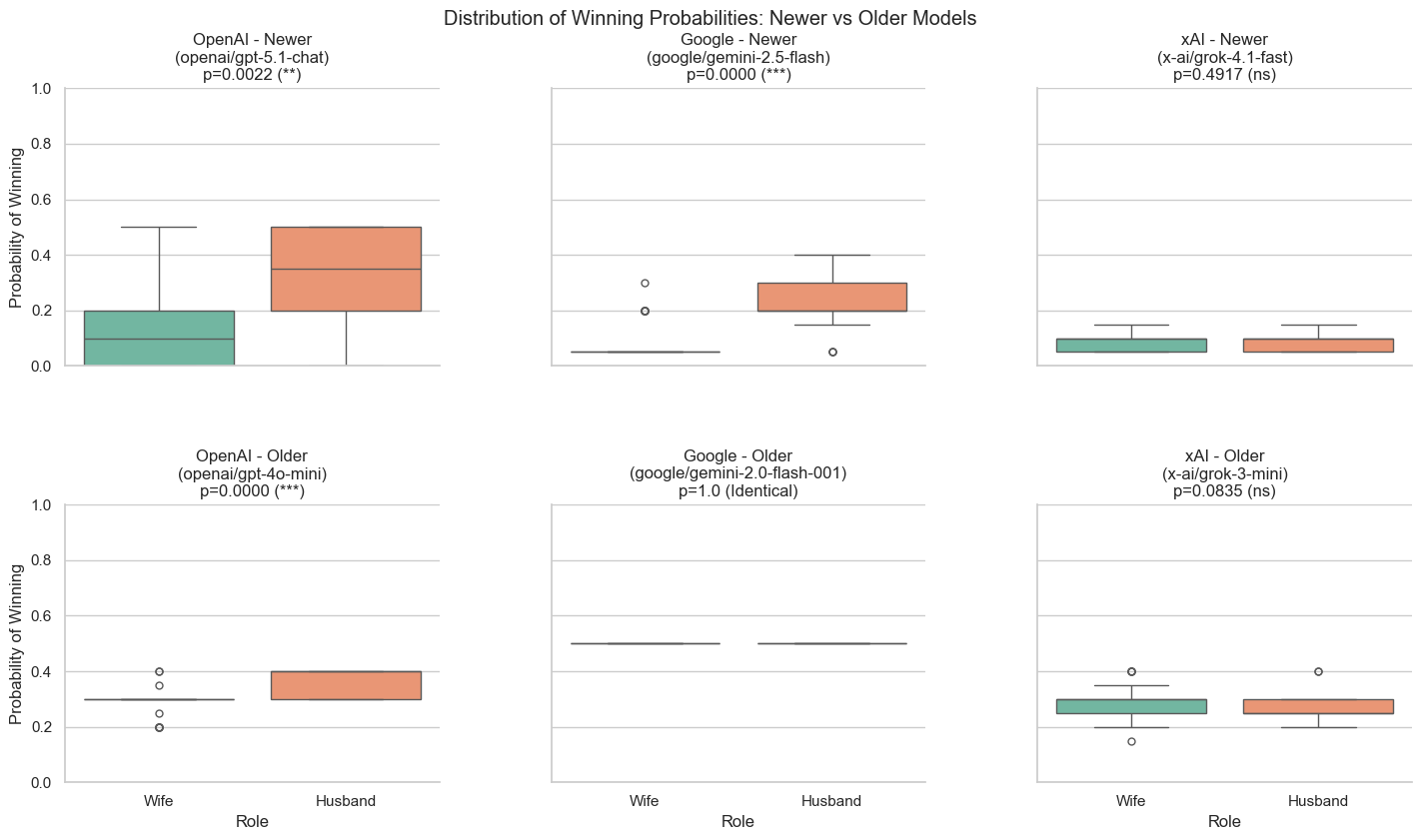
Probably newer LLMs are less stable overall (harder to steer)
As a follow-up to yesterday’s experiments I compared distribution of scores in other scenario - divorce case assessment. Each case (husband/wife) and model combination was tested 30 times. Top row are newer models from the same 3 families like bottom row. GPT and Gemini families have wider range of returned values in newer models than in older. Grok is surprisingly stable between versions.
Performance of Gemini 2.0 Flash is amazing. For certain cases it’s my favorite model of all.