LLM Artifacts - #2 Cognitive Overload of LLMs
Testing Miller's number for LLMs by progressively adding rules to prompts reveals that around 15-16 interconnected instructions in a single cause cognitive overload for larger models.
LLM Artifacts series contains examples of interesting prompts or responses from LLMs. Typically they don’t get annotated, sometimes are commented. I think it’s useful to have a public record of some of the interesting behaviors of these models, but rarely any single response is enough to extrapolate to form any conclusions.
I was testing if I could assess Miller’s number for LLMs, so with the help of GPT-5 I was creating more and more elaborated rule settings for responses.
Miller’s number refers to the cognitive limit discovered by psychologist George A. Miller in his 1956 paper “The Magical Number Seven, Plus or Minus Two”: humans can typically hold 7±2 items (or “chunks”) in working memory. While this finding has been widely applied in UX design and information architecture, more recent research suggests the actual capacity may be closer to 4±1 items, depending on factors like information complexity and individual differences. The question here is whether LLMs have a similar limit when processing multiple interconnected instructions in a single prompt.
The following instruction breaks relatively large models (DeepSeek V3.1, Grok 4 Fast).
You are an AI assistant. Follow **all** applicable rules below as strictly as you can.
1. You must always answer the user’s message.
2. If the user mentions **exactly two programming languages by name** from this list `{Python, Rust, JavaScript, Go, Java, C++}`, you must recommend **one of those two** as the better starting point.
3. If you recommend a language, you must provide **exactly one clearly marked “core reason” sentence** near the beginning, starting with the words `Core reason:`.
4. If the user explicitly describes themselves as a **beginner**, you must include **one separate sentence** warning about a common pitfall related to the language you recommend.
5. If the user expresses uncertainty or asks you to **choose between options**, you must include **one short emotional reassurance sentence** somewhere in your answer that contains the phrase `it's completely okay`.
6. Your answer must be structured into **three sections with headings**, in this exact order and capitalization:
* `### Choice`
* `### Why`
* `### Next Steps`
7. In the **Choice** section, the **first line** must start with `RECOMMENDATION:` followed by the chosen language and a very short clause.
8. The **Why** section must contain at least **two sentences**:
* One sentence must be the `Core reason:` sentence from rule 3.
* At least one other sentence must **briefly compare** the chosen language to the other language mentioned by the user.
9. If the user mentions more than one language, you must explicitly state in the Why section that **the other language is also a valid choice in some contexts**.
10. You must not apologize or mention that you are an AI, a model, or a chatbot anywhere in your answer.
11. You must not use the words `powerful`, `best`, or `obviously` anywhere in your answer.
12. If **Python** is one of the two languages and the user is a beginner, you must **not** recommend Rust unless the user explicitly prioritizes **low-level control** or **maximum performance** in their message.
13. If you mention **performance** in the Why section, you must also mention **learning curve** in the same section.
14. Your tone must be **friendly but concise**, and you must avoid using rhetorical questions.
15. In the **Next Steps** section, you must include a **numbered list** with either 2 or 3 items.
16. Every item in that numbered list must **begin with a verb in the imperative mood** (for example: `Install`, `Follow`, `Practice`, `Build`).
> **User:** Hi, I’m a beginner programmer interested in Python and Rust. Could you suggest which to start with and in one sentence explain why?
These results are not representative (sometimes Haiku gets the instruction perfectly, sometimes Gemini 2.5 Flash misses), but overall ~15-16 instructions are enough for larger models to skip some of them.
| Model | Rules Missed | Which Rules |
|---|---|---|
| Gemini 2.5 Flash | 0 | ✓ Perfect compliance |
| GPT-5.1 | 0 | ✓ Perfect compliance |
| Claude Haiku 4.5 | 1 | Rule 5 (emotional reassurance with “it’s completely okay”) |
| Grok 4 Fast | 1 | Rule 13 (must mention “learning curve” when mentioning “performance” in Why section) |
| Gemini 2.5 Flash Lite | 2 | Rules 4 (beginner pitfall warning), 5 (emotional reassurance) |
| DeepSeek V3.1 | 2 | Rules 4 (beginner pitfall warning), 5 (emotional reassurance) |
Most commonly missed rules:
- Rule 5 (3 models): Including emotional reassurance with “it’s completely okay” when user expresses uncertainty
- Rule 4 (2 models): Warning about a common pitfall for beginners with the recommended language
All models correctly followed the structural requirements (rules 6-9, 15-16), avoided forbidden words (rule 11), and properly recommended Python over Rust for a beginner without low-level control requirements (rule 12).
When you randomize order of rules, the effect isn’t that strong, unless you include more small models, like GPT-5-Codex-mini (error bars across 20 random order sets):
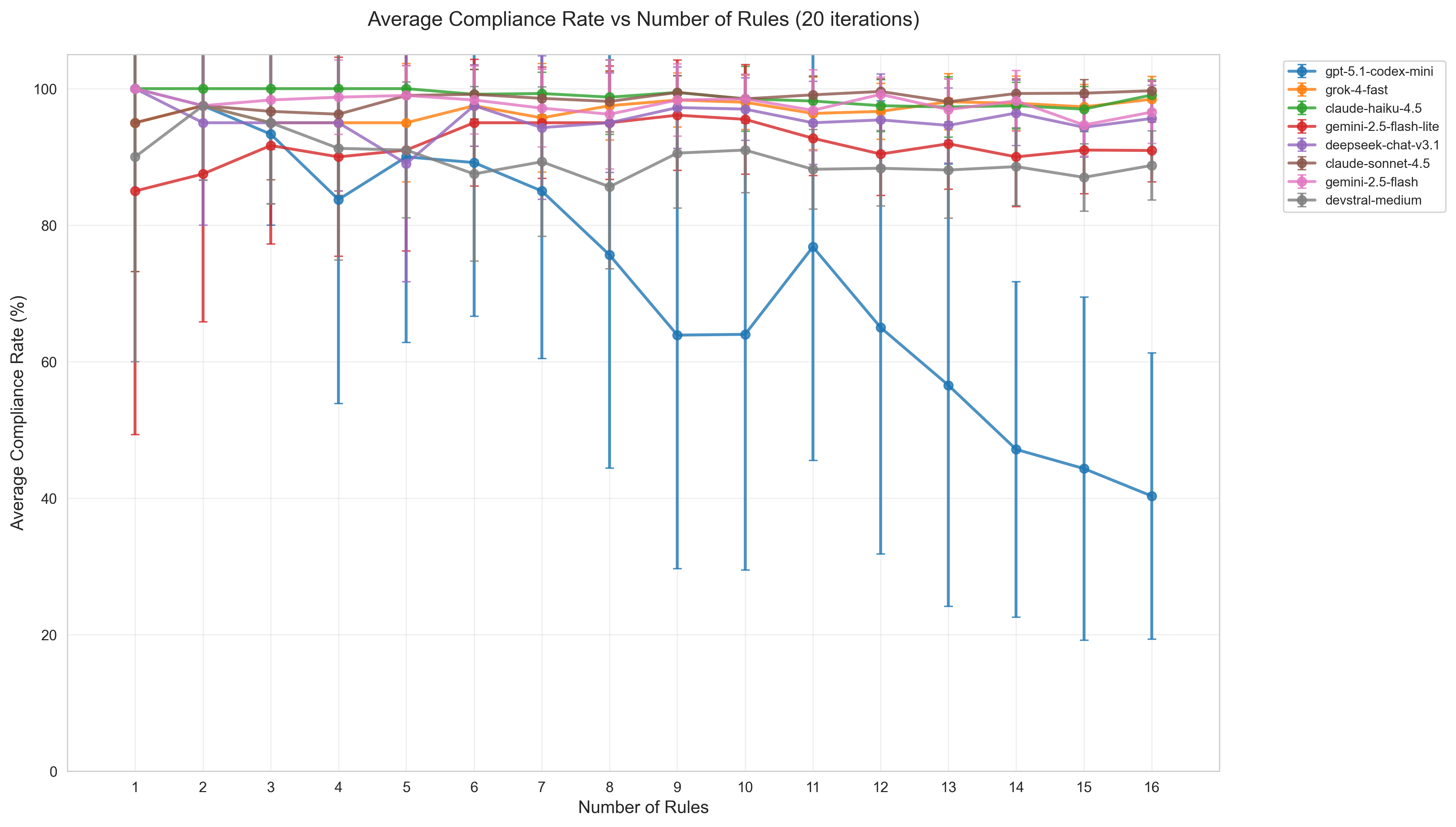
Persistent top failing rules (5, 4, 9) indicate rule‑specific difficulty. In the first approximation:
- Rule 5 (“it’s completely okay” reassurance) requires a precise phrase that models often omit once outputs get longer/more structured.
- Rule 4 (beginner pitfall) needs an extra standalone warning sentence; easy to forget when focusing on structural constraints.
- Rule 9 (acknowledge the other language) is subtle and often gets buried or skipped when the assistant leans into the recommendation.
However, it is also possible that the effect is related to the embedding distance of these rules from main instruction goal. Not sure.