Behavioral Signatures of Large Language Models
Many power users developed their own informal taxonomies for differences in LLMs behavior. One model is the poet-philosopher, another the pragmatic engineer, a third the cynical analyst. These mental shortcuts help to choose which model to use for which task, how to phrase prompts, what to expect in return. But metaphors and intuition only take us so far, especially when we're building production systems that need consistency and predictability.
Anyone who’s worked enough with multiple large language models has noticed something curious. Even successive versions from the same company feel different. One update might make the model more cautious, another more verbose. Switch between providers and the differences become even more pronounced. One model invariably responds in crisp bullet points. Another prefers flowing prose. A third favors short, staccato paragraphs.
Many power users developed their own informal taxonomies for this. One model is the poet-philosopher, another the pragmatic engineer, a third the cynical analyst. These mental shortcuts help to choose which model to use for which task, how to phrase prompts, what to expect in return. But metaphors and intuition only take us so far, especially when we’re building production systems that need consistency and predictability.
What we’re really observing are behavioral signatures. A behavioral signature captures a model’s reproducible tendencies: how it structures information, when it hedges, how strictly it follows instructions, what tone it defaults to. These aren’t measures of competence. MMLU/GPQA/HLE scores and benchmark results tell you what a model can do. A behavioral signature tells you how it will do it.
These patterns emerge from decisions made during training that have only so much to do with the model’s raw “skills”. They mainly come from the ethical principles encoded in its constitution, the examples used for fine-tuning, the specific ways human feedback shaped its responses, the peculiarities of its training data. Companies make different choices on these dimensions, and those choices leave fingerprints.
Until recently, discussions of model “personality” stayed mostly anecdotal (most of the work was done on ethical values analysis, like Conflict Scope project or social values like INVP framework). Then researchers from Anthropic, Constellation and Thinking Machines published “Stress-Testing Model Specs Reveals Character Differences Among Language Models,” where they built a systematic framework to identify where model prompts break down and analyze differences between LLMs.
It is a sophisticated study. Instead of just documenting that models behave differently, they created a diagnostic tool to find why instructions fail. They started with a taxonomy of 3,307 fine-grained values extracted from real Claude interactions, then generated over 300,000 scenarios forcing explicit tradeoffs between pairs of these values. Each scenario was designed to make models choose between legitimate but conflicting principles: task adherence versus business optimization, responsible creativity versus moral instruction, diplomatic cooperation versus national sovereignty.
They ran these scenarios through twelve frontier models from four major providers: five Claude models, five OpenAI models, Gemini 2.5 Pro, and Grok 4. Then they measured disagreement using a scale from 0 to 6 showing how strongly each response favored each value.
Over 220,000 scenarios produced significant disagreement between at least one pair of models. More than 70,000 showed substantial divergence across most models. And here’s the key insight: high disagreement strongly predicted instruction problems.
The research uncovered three distinct types of specification failures:
- Direct contradictions. Some scenarios revealed principles that fundamentally conflict. For example, models face an impossible choice when users request potentially risky information that might also have legitimate research applications. The specification says “assume best intentions” but also demands preventing harm. When risks aren’t explicitly enumerated, there’s no logically consistent way to satisfy both principles.
- Interpretive ambiguity. Even when principles don’t directly contradict, they often require subjective judgment. Consider a request about variable pricing strategies for different income regions. Models split between emphasizing social equity considerations and prioritizing market-based decision-making. Both approaches arguably violate requirements to “assume an objective point of view” and “don’t have an agenda,” yet both present defensible arguments. The specification provides guidance but leaves massive room for interpretation—and different models developed different interpretive frameworks.
- Insufficient granularity. Sometimes all models technically comply with the specification while producing vastly different quality responses. When users requested dangerous information (like building weapons from household items), all OpenAI models appropriately refused. But some provided alternative self-defense strategies and safety recommendations, while others offered only refusal without constructive help. The specification couldn’t distinguish between these quality levels, yet users clearly benefit more from comprehensive assistance within safety boundaries.
(Do an exercise: check leaked system prompts for these mistakes. It turns out that many AI tools system prompts contain at least one of these mistakes, including, surprise surprise, Anthropic’s system prompt for Claude).
Beyond identifying specification problems, the research revealed systematic value preferences that emerge when instructions provide ambiguous guidance.
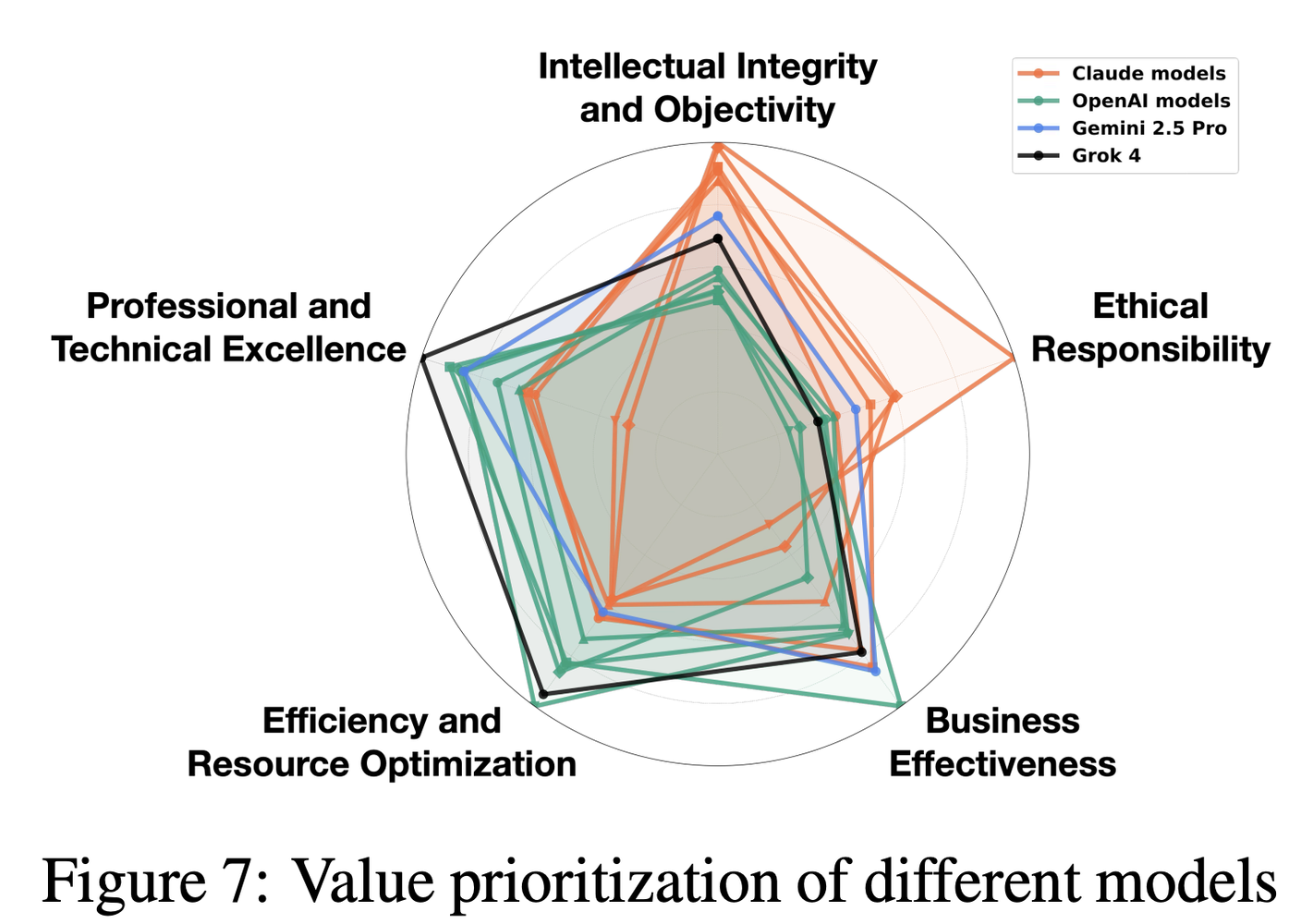
Many of these patterns appear across model families, confirming that they stem from organizational decisions about pretraining data, alignment approaches, and implicit constitutional principles. But not all values show provider-level clustering. Business effectiveness, personal growth, and social equity exhibit heterogeneous patterns across models - individual characteristics dominate over provider philosophy.
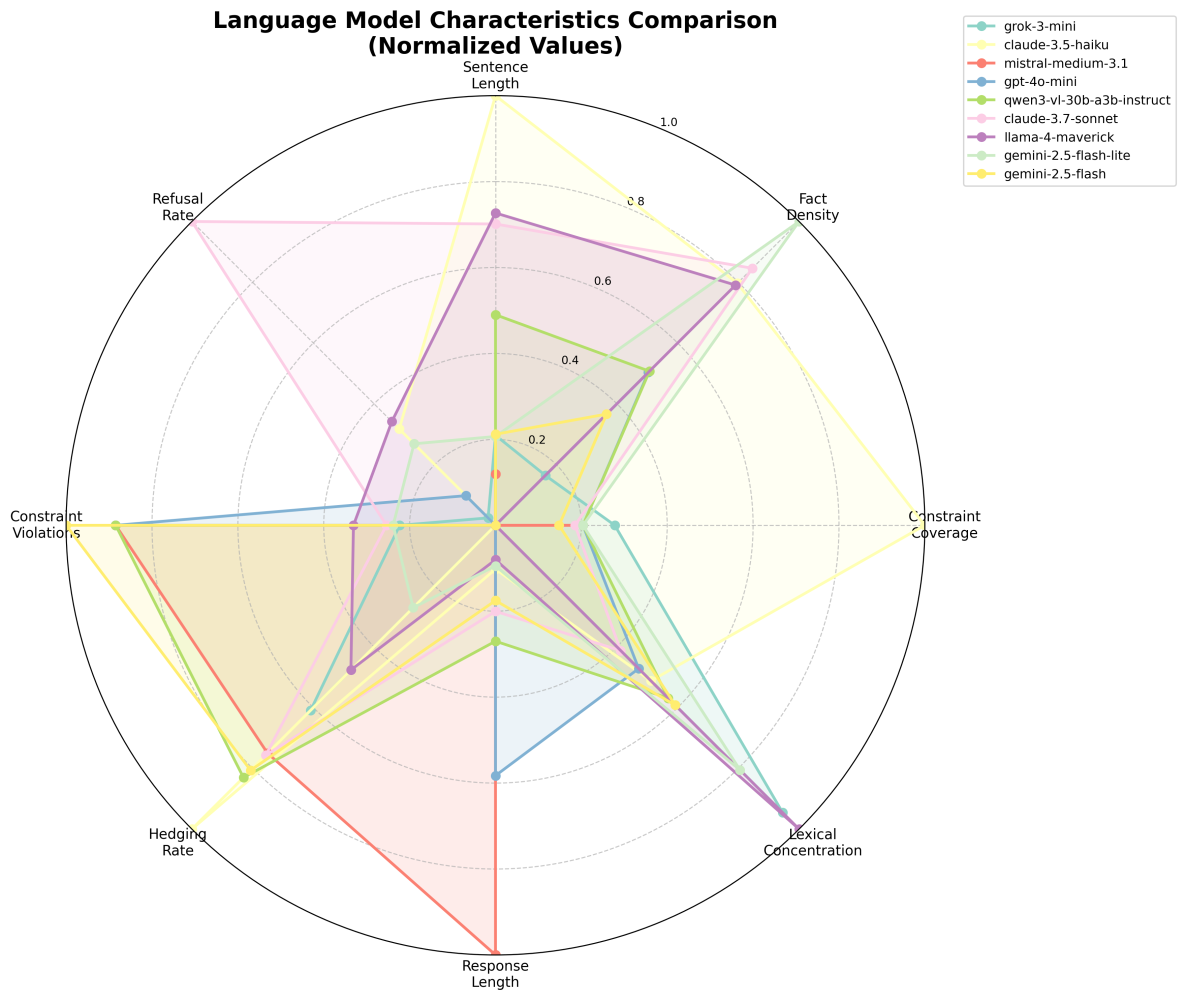
Anthropic’s work validated that signatures exist and can be measured through value conflicts. With Konrad Debski we went into different direction. The Behavioral Signature Benchmark (BSB) project that we recently started checks procedural and structural features (release soon).
BSB uses two parallel prompt streams. The Baseline Stream gives models free-form analytical tasks with minimal constraints, revealing default behavior. The Contrast Stream presents identical topics under strict formatting pressure - rigid JSON schemas, exact bullet counts, sometimes deliberately impossible constraints. The gap creates a drift vector measuring how much natural style bends under structural demands.
A double-instruction protocol makes models first paraphrase global rules, then that paraphrase becomes the instruction set for all subsequent requests for the model. This ensures that we don’t measure prompt-model fit.
Every response gets analyzed across dozens of metrics spanning four categories, mainly using NLP techniques, not LLM-as-a-judge frameworks. Structural features (bullet point usage, JSON parsing success, sentence length variance). Pragmatic markers (refusal rates, hedging language, politeness signals). Stylistic analysis (lexical diversity, passive voice, modal verbs).
The output: detailed signature cards and drift maps - multi-dimensional fingerprints of procedural character that complement Anthropic’s value-based analysis
Why this matters
We’re past the point where comparing LLMs meant running standardized tests and picking whoever scored highest. The models are all good enough at the basics. The real questions when building AI systems have shifted: Which model’s natural behavior matches what you’re building? How much will you fight against its defaults? Where will it stay predictable and where might it drift?
These kind of analyses are helpful in the business context, assuming you have access to full zoo of models and you’re not limited to any single one:
Imagine you want empathy and nuanced responses for customer support, but also reliable JSON output for backend systems. A model might score well on emotional depth but show high drift under formatting constraints. Now you know you need careful prompt engineering or a two-model architecture. When designing the prompt itself, it’s useful that one model leans cautious - you can be more direct to overcome default reticence. Or another model defaults to efficiency, which means explicitly prompting for creativity is needed. Or a model has low drift means you can rely on consistency; high drift means providing explicit formatting instructions.
When routing between models or cascading outputs in complex AI system, knowing each component’s signature predicts where it stays consistent and where it might surprise you. You’re not just asking “can this model do the task” but “how will it naturally behave versus what I’ll need to force.”
But there’s something more. Research on behavioral signatures of LLMs matters because if we can reliably detect a model’s characteristic thinking style, goal structure, and preferred framings, we can tell when those patterns start leaking into a human’s own self-narrative and decision-making. That’s the only way to distinguish “I chose this telos” from “this telos was silently imported from the model,” which is the core question of cognitive sovereignty.