(Last modified: 2025-06-09)
This guide was originally written for AI enthusiasts participating in the AgentON hackathon, who needed to stabilize and thoroughly test prompts for LLMs under tight time constraints.
Introduction
In a hackathon, your AI solution will be tested by other participants (often actively trying to break it). While building a functioning demo is already difficult, creating an LLM-based agent that remains stable under peer testing is the real challenge. Within 24 hours, you need to develop a solution that handles unexpected inputs, edge cases, and creative testing scenarios from your peers.
The problem with agentic systems is resilience. Advanced language models behave more like creative conversationalists than deterministic programs - the more sophisticated the model, the harder it becomes to ensure consistent outputs. John Rush, an AI builder on X, captured this frustration perfectly:
In typical scenarios large language models behave like creative humans - ask the same question twice, get two different answers (unless you control parameters beyond those exposed by API providers, meaning you self-host the model). Pretty annoying for a tech that was supposed to power AI agents.
Fortunately, you can control some of this variance through prompt engineering. Lower temperature settings force more deterministic outputs (usually). Structured formats like JSON constrain possible responses. Clear examples and explicit instructions in your prompts guide the model toward consistent patterns. Finally, roles and personas can further make the agent more robust.
Your approach should anticipate, assess and trigger variance during the development process to ensure that your agentic system can really operate on its own.
Basics of LLM Stabilization
Statistics Is Your Friend
When Anthropic published their approach to statistical LLM evaluations, AI developers on Twitter/X split into two camps (link to the post: https://www.anthropic.com/research/statistical-approach-to-model-evals). Some embraced it, while others rejected the idea that complex AI systems could be evaluated using basic statistics. But here’s the truth: they can and should be.
Simple statistical testing - running the same prompt multiple times under identical conditions - reveals system weaknesses quickly. Errors in agent systems cascade rapidly. Without measuring variation, you’re blind to how your system will perform under thorough peer testing.
Start by testing each prompt-input combination 20-50 times at your target settings. This reveals both the variety of responses and their error rate. Perfect accuracy? Great - focus on parsing those varying responses correctly, especially with structured outputs. But don’t rush to test different inputs until your base instruction performs reliably. Many developers skip ahead too quickly, testing input variations before their core instruction is stable.
If accuracy falls below 90%, particularly around 30%, you need to revise your instruction or reconsider your model choice. No amount of optimization will fix a fundamentally unstable foundation.
Token Choices Matter More Than Temperature
Many developers rely on setting temperature to 0 for stability. The reality is more complex. A simple word substitution in your prompt can destabilize outputs regardless of temperature settings. Let me demonstrate with our compass direction experiment.
A seemingly harmless word swap in your prompt can destabilize outputs or break your system entirely, independently of temperature settings. We gave GPT-4o-mini a simple task: list compass directions clockwise from North. The baseline prompt defined compass points and requested cardinal and intercardinal directions in clockwise order. Expected output was straightforward: north, northeast, east, southeast, south, southwest, west, northwest. The crucial element of the experiment: original instruction was written by the model of the same family (GPT-4o).
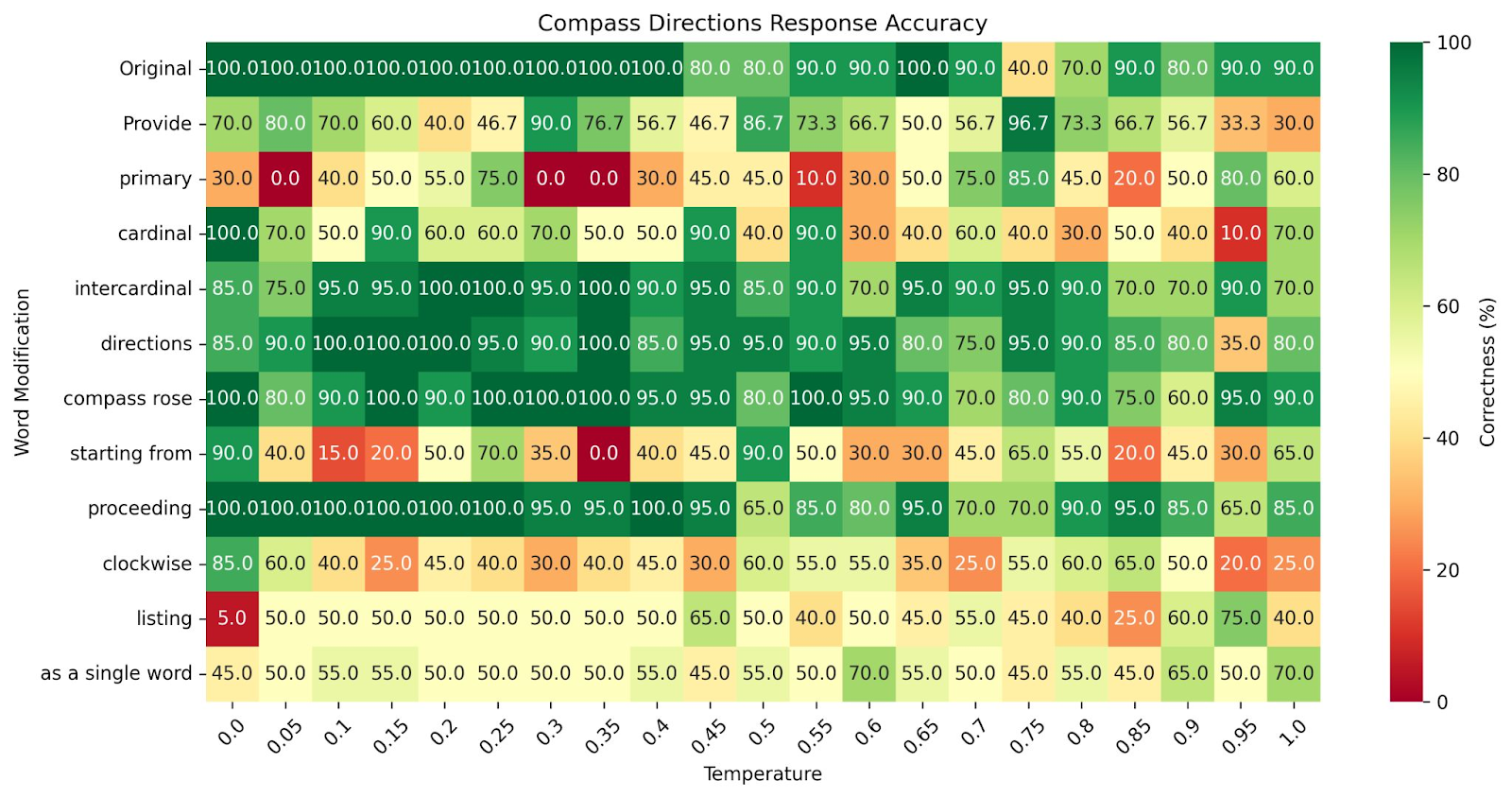
We tested prompt stability through systematic word substitutions in the instruction and variations in the temperature parameter. Each variant was run 10 times. The result? Kind of chaos. Some word substitutions were neutral, others resulted in lower accuracy, some made the model respond in the wrong way 100% of times (we searched for a correct word order, however formatted and with or without hyphens). Temperature changes affected consistency, but not in the linear way you might expect - higher randomness didn’t always mean worse performance. Original instruction was among the most stable (some combinations were similar).
Lesson: rewrite your agent prompts using the target model or a model from the same family. That would ensure that the choice of tokens in the instruction is better aligned with the model’s latent space. Instructions are not transferable between model families without rewriting.
Myth of Structured Output
JSON output simplifies agent development by making responses easier to parse. Many AI builders claim it also makes models more robust, with less response variation. Our testing suggests it’s not always the case.
Using GPT-4o-mini, we compared plain text versus JSON output for compass directions. Surprisingly, the plain text version produced fewer response variants across all experiments. The JSON version consistently showed higher error rates in runs of 20, 50, and 100 iterations. This challenges the common assumption that structured output inherently improves stability.
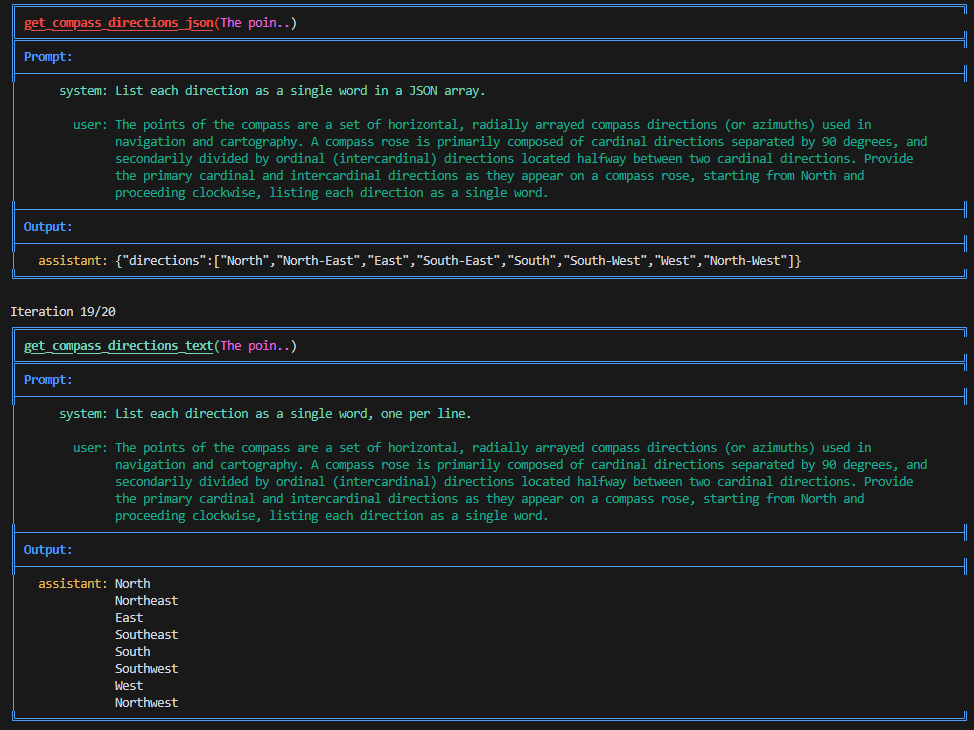
The lesson is clear: use JSON when you need structured data, not as a stability enhancement. When in doubt, test your instruction repeatedly - the results often contradict conventional wisdom.
Agent Roles or Personas
Some AI agent frameworks come with pre-built agents with roles (like “tech leader”, “business analyst”, “hr director”, sometimes with long instructions and extensive backstories. Quite often it helps in getting better results, but I rarely see anybody testing if they really help.
Many AI frameworks include pre-built agents with defined roles - tech leaders, business analysts, HR directors - often with extensive backstories. While these can improve results, their effectiveness is rarely tested systematically. In our compass experiment with GPT-4o-mini, the baseline instruction achieved 90% accuracy at temperature=1. We tested two versions of a Carl Friedrich Gauss persona: a generic version achieved 97% accuracy, while a task-optimized version dropped to 23% accuracy over 100 runs.


This counterintuitive result led to broader testing. We generated multiple personas and tested them against our compass instruction with synonym replacements. The baseline approach averaged 65% accuracy (over all replacements). A navigation-specific persona and an unrelated “poet” persona showed slight improvements, while a “veteran maritime assessor” - seemingly ideal for the task - performed significantly worse.
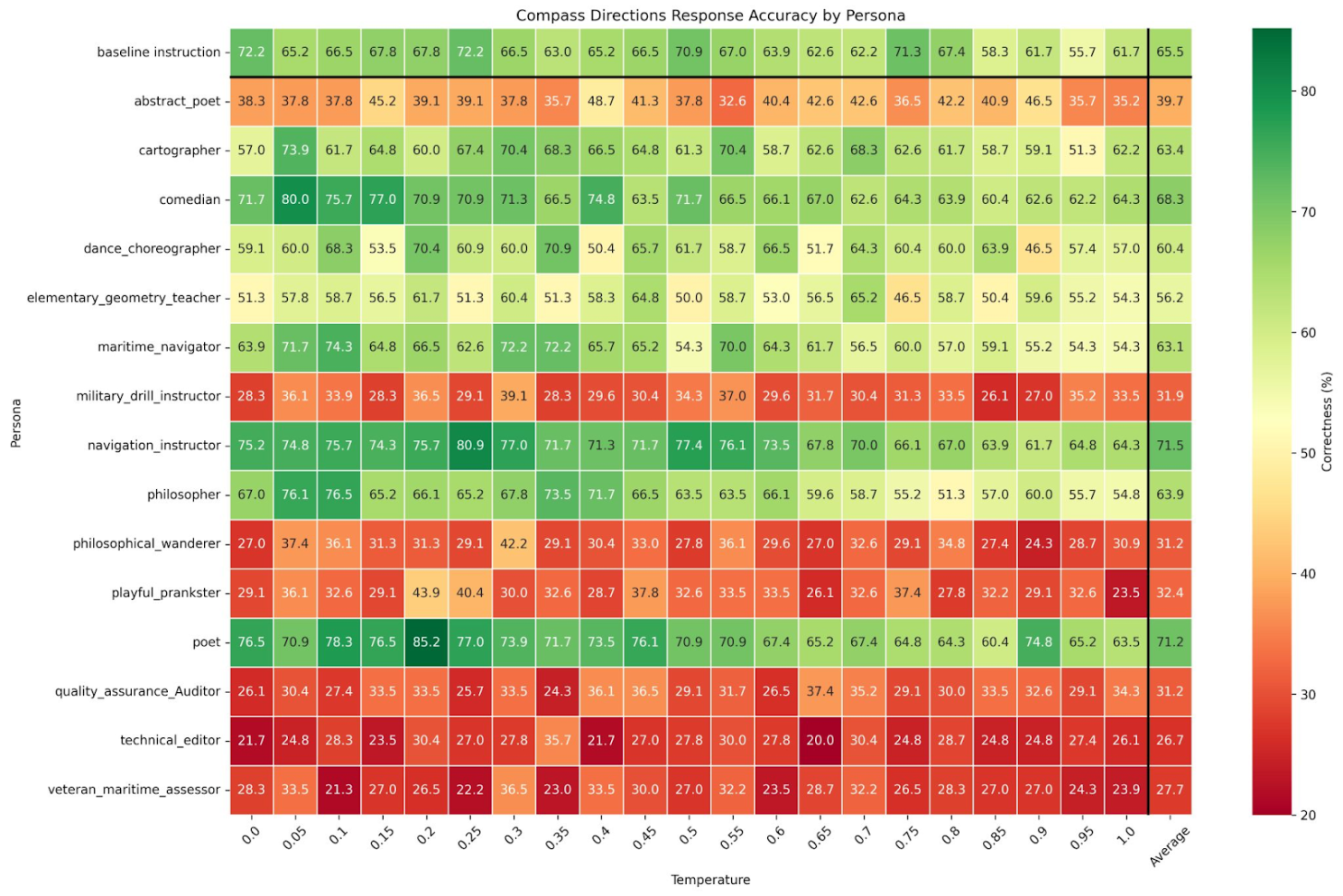
The takeaway? Personas can enhance stability, but finding the right one requires testing, not intuition. Don’t assume that topic-relevant personas automatically perform better.
Synthetic Data as Testing Inputs
Using generative models to create test data seems straightforward, but requires two key considerations. First, avoid using the same model family for generating test data as you use in your agent. If your agent uses OpenAI models, generate test data with Gemini, or vice versa. You want imperfect token combinations that better reflect real-world usage. Perfect token alignment in test data creates a false sense of stability. Second, leverage personas to generate diverse input data rather than relying on your team’s imagination. Tencent’s persona-hub dataset provides an excellent resource, offering synthetic personas ranging from political analysts to sports enthusiasts. It is available at: https://github.com/tencent-ailab/persona-hub/tree/main and personas descriptions are released in a simple format like this:
{"persona": "A Political Analyst specialized in El Salvador's political landscape."}
{"persona": "A legal advisor who understands the legal implications of incomplete or inaccurate project documentation"}
{"persona": "A maternal health advocate focused on raising awareness about postpartum complications."}
{"persona": "A school basketball team captain who believes sports and their funding should be prioritized over student council campaigns"}
{"persona": "A determined basketball player who aspires to be the star athlete of the school"}
{"persona": "A virtual reality content creator sharing their experiences and creations on a popular online platform"}
When combined with less constrained models than OpenAI’s ones, like Gemini-Flash-8b, these personas generate realistic input variations that effectively simulate user behavior. Remember, your production system will face unpredictable inputs. Testing against diverse, imperfect data helps build genuine resilience.
Summary
Building stable AI agents for hackathon evaluation comes down to three critical insights: First, trust data over intuition. Run each prompt 20-50 times to measure stability - if accuracy drops below 90%, fix your foundation before optimizing. Second, common stabilization techniques often fail: temperature settings matter less than word choice, JSON doesn’t inherently improve stability, and topic-relevant personas don’t automatically perform better. Finally, test with imperfect data. Generate test inputs using different model families and diverse personas to simulate real-world usage. The key to success isn’t following best practices blindly - it’s measuring everything systematically. A stable agent requires less creative problem-solving and more methodical testing than most developers expect.